
HTML - 预解析, async/defer 和 preload
本文是关于 @mactavish 学弟在众成翻译上翻译的文章 更快地构建 DOM: 使用预解析, async, defer 以及 preload ★ Mozilla Hacks – the Web developer blog 的阅读笔记。特此感谢。
Parsing
首先我们需要了解浏览器正常的文档解析流程(Parsing):
- 浏览器引擎的解析器会将 HTML 转换成 DOM(解析,DOM 的构建)
- 在解析 HTML 字符串的过程中,DOM 节点逐个被添加到树中
- 在 DOM 中,对象被关联在树中用户捕获标签之间的父子关系
- CSS 样式被映射到 CSSOM 上
- CSS 规则会互相覆盖,所以浏览器引擎需要进行复杂计算,以确定 CSS 代码如何应用到 DOM
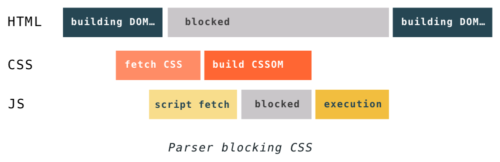
- CSS 可能会阻塞解析:
- 当解析器获取一个
<script>标签时,DOM 将等待 JavaScript 执行完毕后继续构建; - 若有 CSS 样式表先于该标签,则该标签的 JavaScript 代码将等待 CSS 下载,解析,且 CSSOM 可以使用时,才会执行
- 当解析器获取一个
- CSS 会阻塞 DOM 的渲染:直到 DOM 和 CSSOM 准备好之前,浏览器什么都不会显示。
- FOUC - Flash of Unstyled Content: 没有任何样式的页面突然变换成了有样式的。
CSSOM
CSS Object Model is a set of APIs allowing to manipulate CSS from JavaScript…It allows to read and modify CSS style dynamically.
一系列的可以操作 CSS 样式的 JS 方法。
CSS.supports
@supports CSS at-rule
1 | @supports (display: flex) { |
预解析 Speculative Parsing
它的概念是:虽然在执行脚本时构建 DOM 是不安全的,但是你仍然可以解析 HTML 来查看其它需要检索的资源。找到的文件会被添加到一个列表里并开始 在后台并行地下载 。当脚本执行完毕之后,这些文件很可能已经下载完成了。
说人话:就是会提前的下载 HTML 页面上声明了的脚本…
下载是并行的,执行是先后的,以这种方式触发的下载请求称为”预测“,因为很有可能脚本还是会改变 HTML 结构,导致预测的浪费(即下载的脚本是无效的,并不会被执行),但这并不常见,所以预解析仍然可以带来很大的性能提升。

- 预加载的内容:
- 脚本
- 外部 CSS
- 来自
<img>标签的图片 - Firefox 预加载 video 元素
poster属性 - Chrome/Safari 预加载
@import内联样式
- 预加载会受到浏览器并行下载文件的数量限制(HTTP 1.x),如 Chrome 浏览器最多只能并行下载6个文件。
- 预解析时,浏览器不会执行内联的 JS 代码块。
- 用 JS 加载不那么重要的内容来避免预解析,这里的意思是说,页面上某些不重要的脚本,相比于其他必需脚本来说,是应该 迟下载,迟执行 的,通过用 JS 动态加载它们,它们就不会一开始出现在 HTML 文档的
<script>标签中,则浏览器的预解析不会处理它们(相对的就会更优先的解析必需脚本)
MDN 的文档 中提到:
- Firefox 4 及之后的版本的 HTML 解析器支持在预解析时不使用浏览器的主线程,从而可以达到不阻塞正常 DOM 构建和渲染的效果。
- 尽量确保预加载成功:如果使用了
<base>元素指定页面加载资源的根地址(base URI),则确保不要用 JS 去加载该元素(注:放到<head>标签里就可以了) - 避免预解析构建的 DOM 树失效,这里需要避免一些对
document.write方法的滥用,具体可以看 MDN 文档中 “Avoid losing tree builder output” 一节中列出的几个点
defer 和 async
defer和async在下载时都不会阻塞 HTML 解析器的执行(解析 DOM)defer和async之间的不同是他们开始执行脚本的时机的不同defer脚本在 HTML 文档解析完全完成之后才开始执行,处在DOMContentLoaded事件之前。保证脚本会按照它在 HTML 中出现的顺序执行,且不会阻塞解析但根据红宝书的说法,在一个页面中最好只有一个带
defer的脚本;保险起见,在DOMContentLoaded的事件回调中执行实际的业务代码:HTML5规范要求脚本按照它们出现的先后顺序执行,因此第一个延迟脚本会先于第二个延迟脚本执行,而这两个脚本会先于DOMContentLoaded事件执行。在现实当中,延迟脚本并不一定会按照顺序执行,也不一定会在 DOMContentLoaded 事件触发前执行,因此最好只包含一个延迟脚本。
红宝书的说法是有实锤的,在 这个issue中 有人做了实验确认了 Firefox 在处理
defer属性脚本时,脚本的代码是在DOMContentLoaded事件后才执行的;同时,在 IE<=9 时,defer脚本的顺序执行也不能保证。
async脚本在它们完成下载后的第一时间执行,它处在 window 的load事件之前,有可能(并且很有可能)设置了 async 的脚本不会按照它们在 HTML 中出现的顺序执行,它们可能会中断 DOM 的构建。- 多个
async脚本之前的执行顺序不总是它们的出现顺序,而取决于 哪个文件先完成下载 - 经典使用场景:不依赖于 DOM 的第三方脚本,例如 Google Analytics
引用 CSS Tricks 中的描述:
If you use the async attribute, you are saying: I don’t want the browser to stop what it’s doing while it’s downloading this script.
MDN 文档 的说法是:
Dynamically inserted scripts execute asynchronously by default, so to turn on synchronous execution (i.e. scripts execute in the order they were inserted) set async=false
- 多个
- 没有
defer或者async属性的脚本,包括行内脚本(inline scripts)会(在 HTML 解析到时)立刻下载并执行,之后浏览器继续解析页面(文档)「注:即阻塞解析」 - 若同时使用
defer和async,则以async为准,当浏览器不支持async时,回退到defer - 兼容性:
defer在 IE6-9 中的实现有问题(并不按规范实现),IE10+ 完整支持asyncIE10+
- 一张图直观的表达:
preload
使用 <link rel="preload"> 告知浏览器对资源进行预先的加载:
1 | <link rel="preload" href="very_important.js" as="script"> |
as 属性的可能的值有:
- script
- style
- image
- font
- audio
- video
预加载字体需要设置 crossorigin 属性,即使字体在同一个域名下:
1 | <link rel="preload" href="font.woff" as="font" crossorigin> |
preload 目前仅在部分新版本的 Chrome 和 Firefox 上得到支持。
More?
其实还有一个问题:如果有一部分 CSS 是在页面所有的 HTML 加载结束之后再被动态插入,此时的 CSSOM 是否会被重新构建?如果同时又有 JS 脚本需要执行,其先后顺序如何?
所以有空的话,顺便也了解下浏览器运作机制呗:
- How Browsers Work: Behind the scenes of modern web browsers (中文版)
- Quantum Up Close: What is a browser engine?
Reference
- 更快地构建 DOM: 使用预解析, async, defer 以及 preload ★ Mozilla Hacks – the Web developer blog
- Building the DOM faster: speculative parsing, async, defer and preload
- script[defer] doesn’t work in IE<=9
- 浅谈script标签的defer和async
- 使用defer或async加载脚本
- Optimizing your pages for speculative parsing, MDN
- Thinking Async, CSS Tricks
- Async Attribute and Scripts At The Bottom, CSS Tricks
- CSSOM, MDN
<script>element, MDN